
Before you can understand how the Node.js worker thread works, there are a few concepts you need to understand as well. These concepts were explained in your Computer Architecture class but your memory needs to be refreshed.
What are Tasks?
In the context of Computing, Tasks refers to a unit of execution or work to be performed by a computer. It is sometimes referred to as process(which is one of the components of tasks, we will come back to this).
The two(2) major tasks that you and I will focus on in this article are:
-
I/O Tasks: Input/Output tasks are computing operations that involve data transfer or communication between the computer and external devices. When you make an API call to an external server from your backend server or frontend, when you make a database query to fetch the list of products from your e-commerce database, when you read or write files to disk or when you wait for user input, these all fall into I/O tasks.
-
CPU-Intensive Tasks: CPU-Intensive Tasks are those types of computing tasks that require significant processing power and computation time. These tasks can slow down your server performance and impact response times, especially if not managed properly. Some examples of CPU-intensive tasks that might be encountered in web servers are
- Simultaneous User Requests: Handling a large number of simultaneous user requests that involve CPU-intensive processing.
- Image Processing: Resizing, cropping, filtering, and converting image formats.
- Video Encoding/Decoding: Transcoding video files into different formats or resolutions.
- File Compression/Decompression: Compressing or decompressing large files on the server.
- Complex Algorithms: Running algorithms that involve heavy mathematical calculations, such as simulations, statistical analysis, or scientific computing.
- Cryptographic Operations: Encrypting and decrypting data, generating secure hashes, and other cryptographic functions.
- Machine Learning/AI Tasks: Training machine learning models or making predictions using pre-trained models.
How does the Event Loop work?
You already know that Node.js excels in performing I/O bound intensive tasks and it does this in a non-blocking way by offloading all asynchronous I/O tasks to be handled by a built-in Async I/O stack.
When each task is done, the associated callback function is added to either the Task Queue or the Microtask Queue depending on what category of asynchronous operation it is. This in a nutshell explains how the Event Loop coordinates the asynchronous operations in Node.js. The table below shows the type of callback function that will be added to each Queue mentioned above:
| Microtask Queue | Task Queue |
|---|---|
| Promise resolve() or reject() result callback | Callback function for asynchronous operations e.g: fs.readFile() |
| Promise then() or catch block() callback | Timers e.g: setTimeout(), setInterval() |
| process.nextTick() callback | |
| queueMicrotask() callback | |
| MutationObserver() class result |
Node.js will not be the best fit for handling CPU-intensive due to its nature. Node.js is Single-Threaded, What this means in simple terms is that execution of every line of code in a typical file or script happens one line at a time, because of this, lines or executions that take a considerable amount of time say 2 minutes will block execution of the lines that come after it until the 2 minutes elapses and These are typically what CPU-Intensive tasks are.
CPU-Intesnsive tasks like recursively calculating the 50th Fibonacci sequence are typically managed effectively by employing various strategies. Some of these strategies include: scaling by adding more CPU resources like the number of cores used in processing tasks, utilising GPUs or specialised hardware for tasks like image processing or machine learning or Offloading CPU-intensive tasks to background processes or worker threads, allowing the main threads to handle other computations.
Offloading CPU-intensive tasks to background processes or threads, allowing the main threads to handle other computations can be done easily in Multi-Threaded Programming languages like Go, Java and C# which have built-in support for Concurrency and concurrency control.
What is Concurrency?
You probably have a machine which has a CPU with more than 4 cores, but imagine for a second that wasn’t the case. Imagine you want to run a computationally expensive task on a single core machine, how would you run such a task in any programming language of your choice without blocking the execution of other tasks?
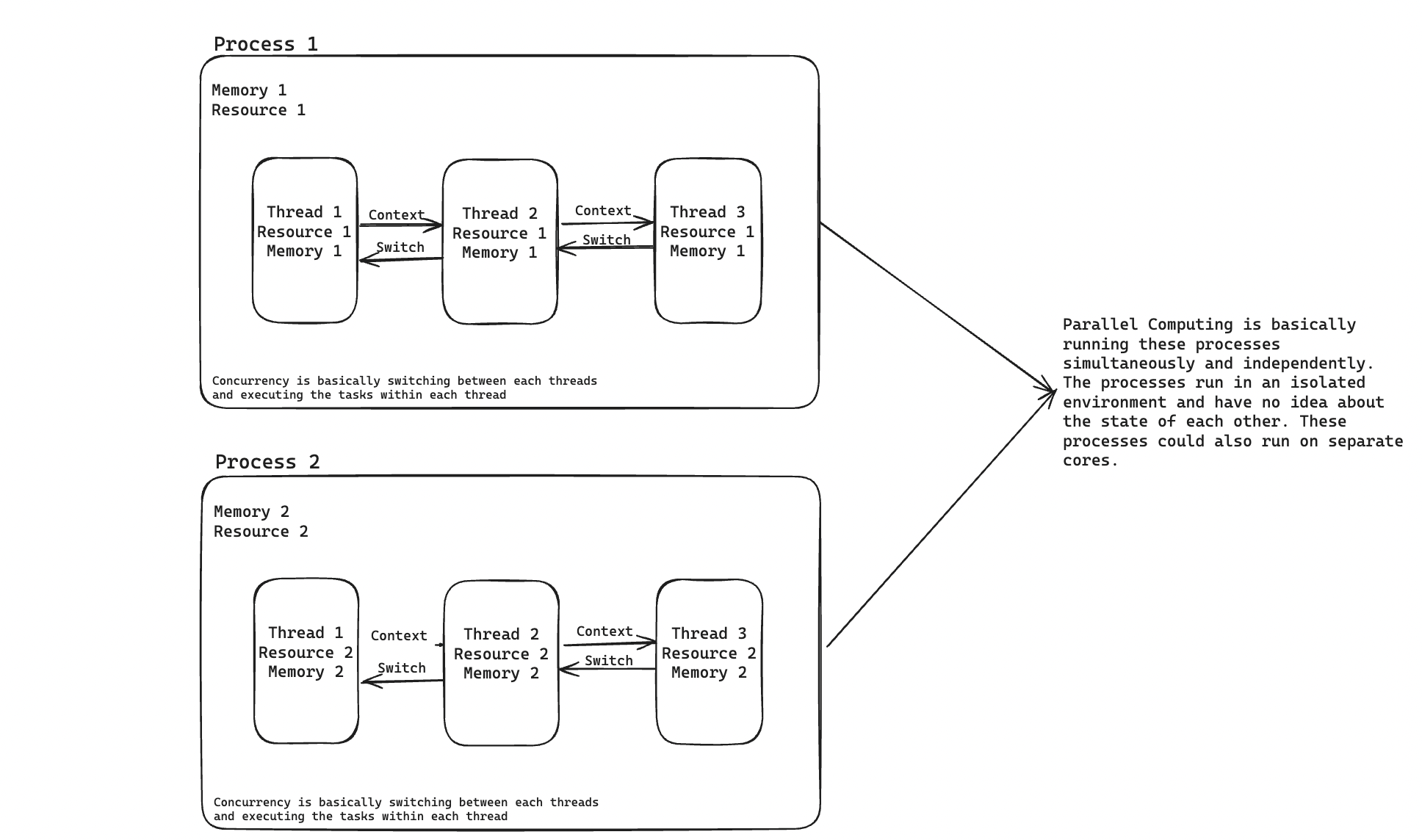
Concurrency is the ability of a computer to deal with multiple tasks(threads) on a single CPU core, the core switches between each task (threads), and each thread does not need to necessarily complete before execution of the next task(thread). Concurrency is often confused with Parallel Computing but they are not the same. In Parallel Computing, processes are carried out simultaneously using multiple CPU cores with each core performing a task independently.
Imagine you were contracted to build a full-stack web application, this application would have an API server, a frontend, and a design. This project would also require a QA tester to test every part of the application to make sure every feature works as expected. If you have the skills and love to have the money paid for the project all to yourself, you can build the entire application by yourself. Let’s say you want to work on the Authentication Module, you can start by designing the Sign up and Sign in flow, start the Forgot Password flow, and then move to implement the UI you just designed, you will probably design just the Sign in screen and then proceed to build out the API endpoints for the Authentication Module which you will most likely not finish as well. Let’s say you were able to build the endpoint for the Sign up, Sign in and Verify Email flow, you would then move back to implement the Sign in screen on the front end. Switching between each task to complete the Authentication Module explains the Concept of Concurrency.
In the context of this analogy, Parallel Computing would be you hiring a designer, a frontend engineer and a QA tester. You can take up the role of building the API server. You and your team would be in a room working independently and simultaneously. The designer designs and the frontend engineer implements each design while you build the API endpoints. These processes happen simultaneously and independently of each other.
One of the similarities between Concurrency and Parallel Computing is that it involves a Process or Processes but what exactly is a process?
A process is an instance of a running program, which includes the program’s code, its current activity, and the resources it utilises (such as memory, file handles, and CPU time). An example will be the designer utilising Figma to convert the app ideas to pixels, frames and screens. Another example will be opening multiple software on your computer say VSCode, Chrome and Postman Desktop app. Each of these applications runs on separate processes in your computer without interference. Processes are isolated from each other, meaning one process cannot directly access the memory or resources of another process. The resources for each process, including CPU scheduling, memory allocation, and I/O operations are all managed by the Operating System. A process can have one or multiple threads.
Processes contain multiple threads(tasks). A thread is the smallest unit of execution within a process. Threads within the same process share the same memory space and resources. Because threads are lightweight(because they are like “subprocesses”) and live within the same memory space provided by the running process, they have lower overhead when switching between contexts.
How to handle Concurrency in Node.js?
Now that you have a clear understanding of tasks, CPU-intensive tasks, processes, threads and other concepts related to Concurrency, how exactly can you achieve concurrency in Node.js?
Remember that Node.js is single-threaded which means, it is not capable of performing CPU-intensive tasks concurrently, one of the ways to achieve concurrency when performing CPU-intensive tasks is by using the Node.js Worker Thread. Worker threads allow you to run JavaScript codes concurrently in separate threads that are different from the main Node process. Each worker runs in a separate V8 isolated background process, with its event loop and memory. Workers can share memory using SharedArrayBuffer and communicate via MessagePort. Worker threads were introduced as an experimental feature in Node.js versions 10.5.0 and stabilized in version 12.
// fibonacci.js
let seconds = 0;
console.log(`Main thread gets stuck after this. Seconds elapsed: ${seconds}`);
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
const n = 50; // Adjust the value for different levels of intensity
setInterval(() => {
seconds += 1;
console.log(`Main thread is responsive. Seconds elapsed: ${seconds}`);
}, 1000);
console.log(`Fibonacci(${n}) = ${fibonacci(n)}`);
The code above calculates the 50th Fibonacci sequence. This function on average will take at least 2 minutes before the computation completes. The image below shows the result of running the code above.

In the image above, if you calculate the difference between Current_Time_After and Current_Time_Before, it will give you an idea of how long the Fibonacci function will take to run before any other line after it will execute. You can see that it takes a considerable amount of time.
//worker.js
const { parentPort, workerData } = require("worker_threads");
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
const result = fibonacci(workerData);
parentPort.postMessage(result);
//main.js
const { Worker } = require("worker_threads");
function runWorker(data) {
return new Promise((resolve, reject) => {
const worker = new Worker("./worker.js", { workerData: data });
worker.on("message", resolve);
worker.on("error", reject);
worker.on("exit", (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`));
});
});
}
const n = 50; // Adjust the value for different levels of intensity
let seconds = 0;
setInterval(() => {
seconds += 1;
console.log(`Main thread is responsive. Seconds elapsed: ${seconds}`);
}, 1000);
runWorker(n)
.then((result) => {
console.log(`Fibonacci(${n}) = ${result}`);
})
.catch((err) => {
console.error(err);
});
When we run the same function using Node.js Worker Threads, we see that the rest of the lines execute without interference from the long-running Fibonacci function unlike before. The image below shows the result.
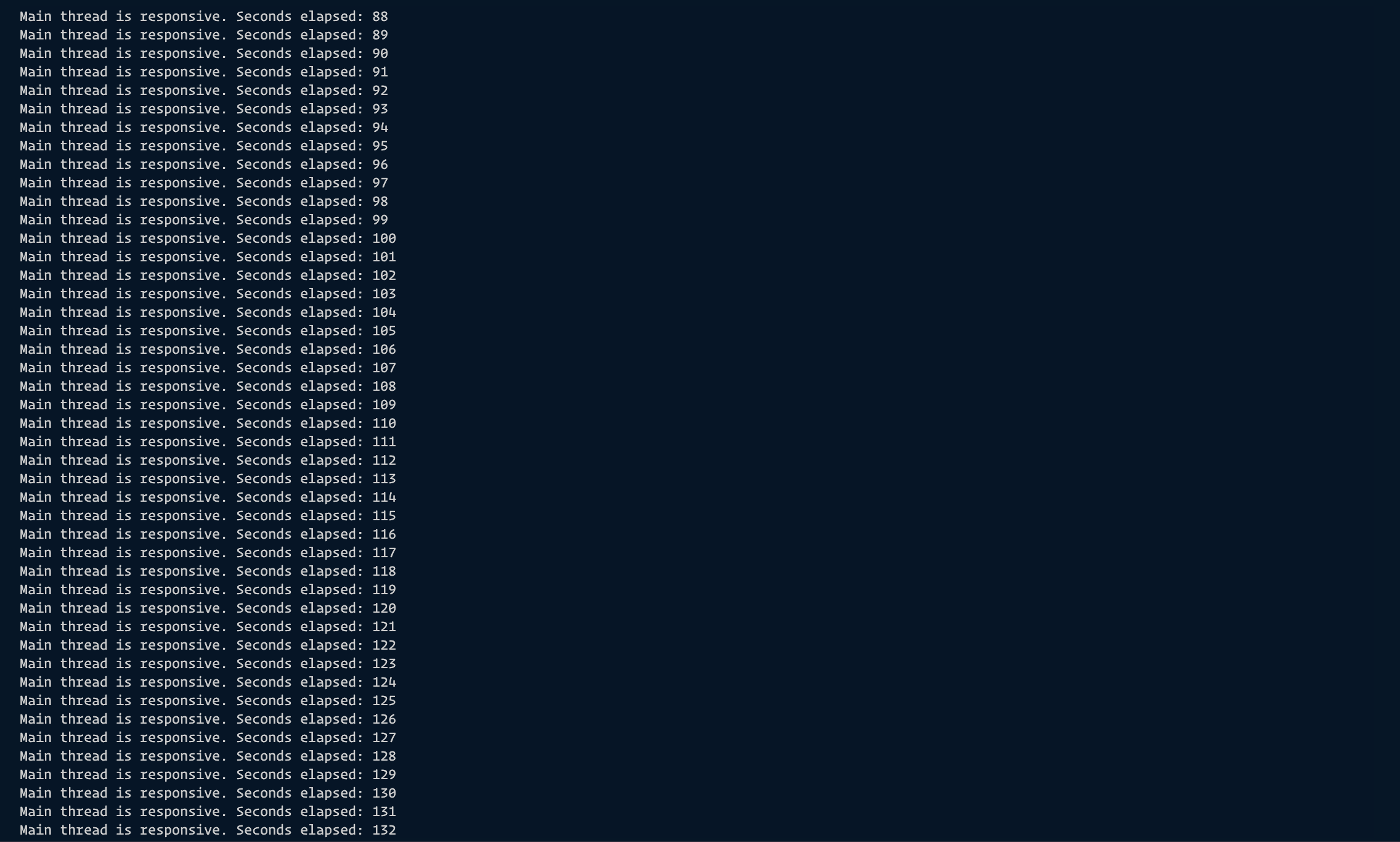
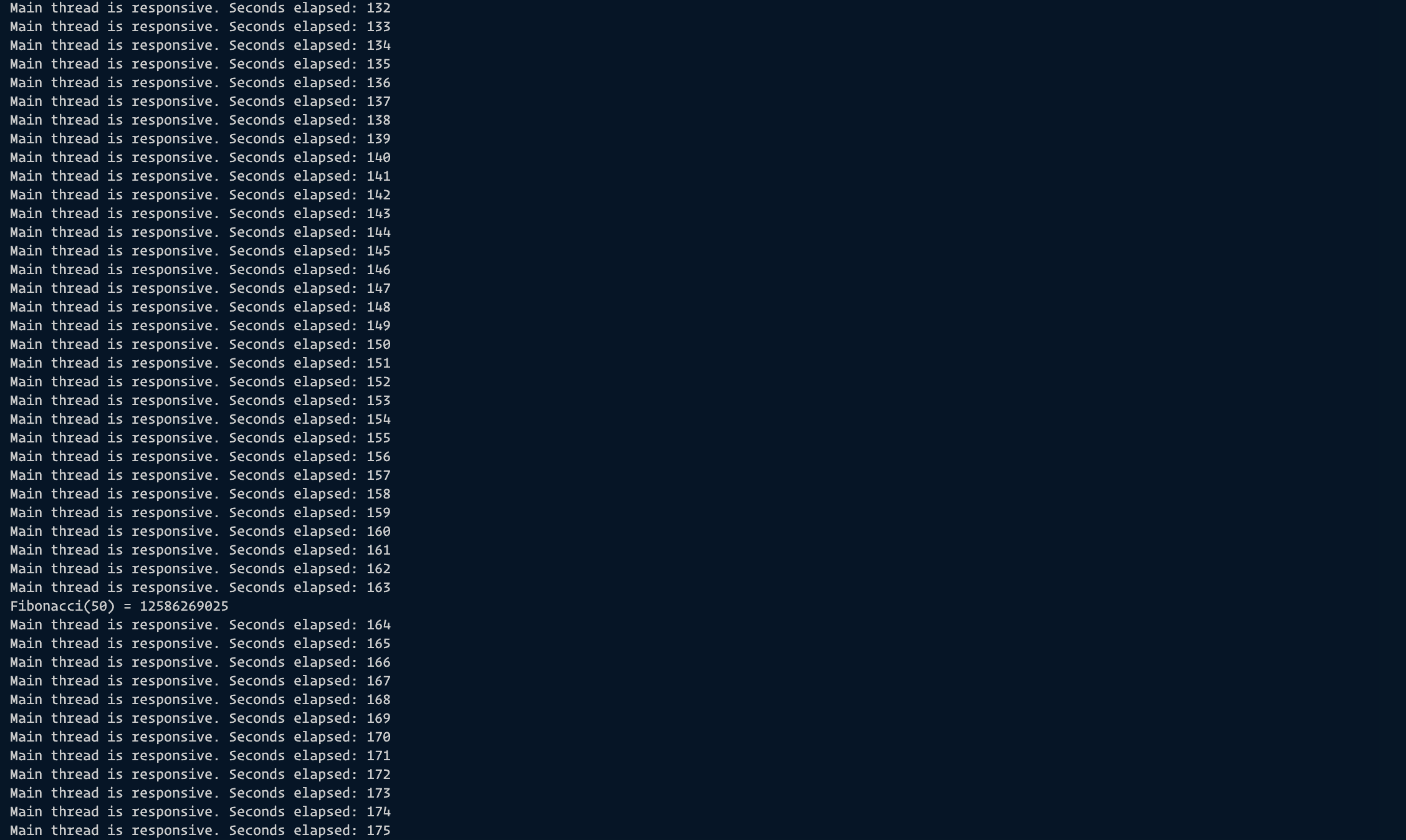
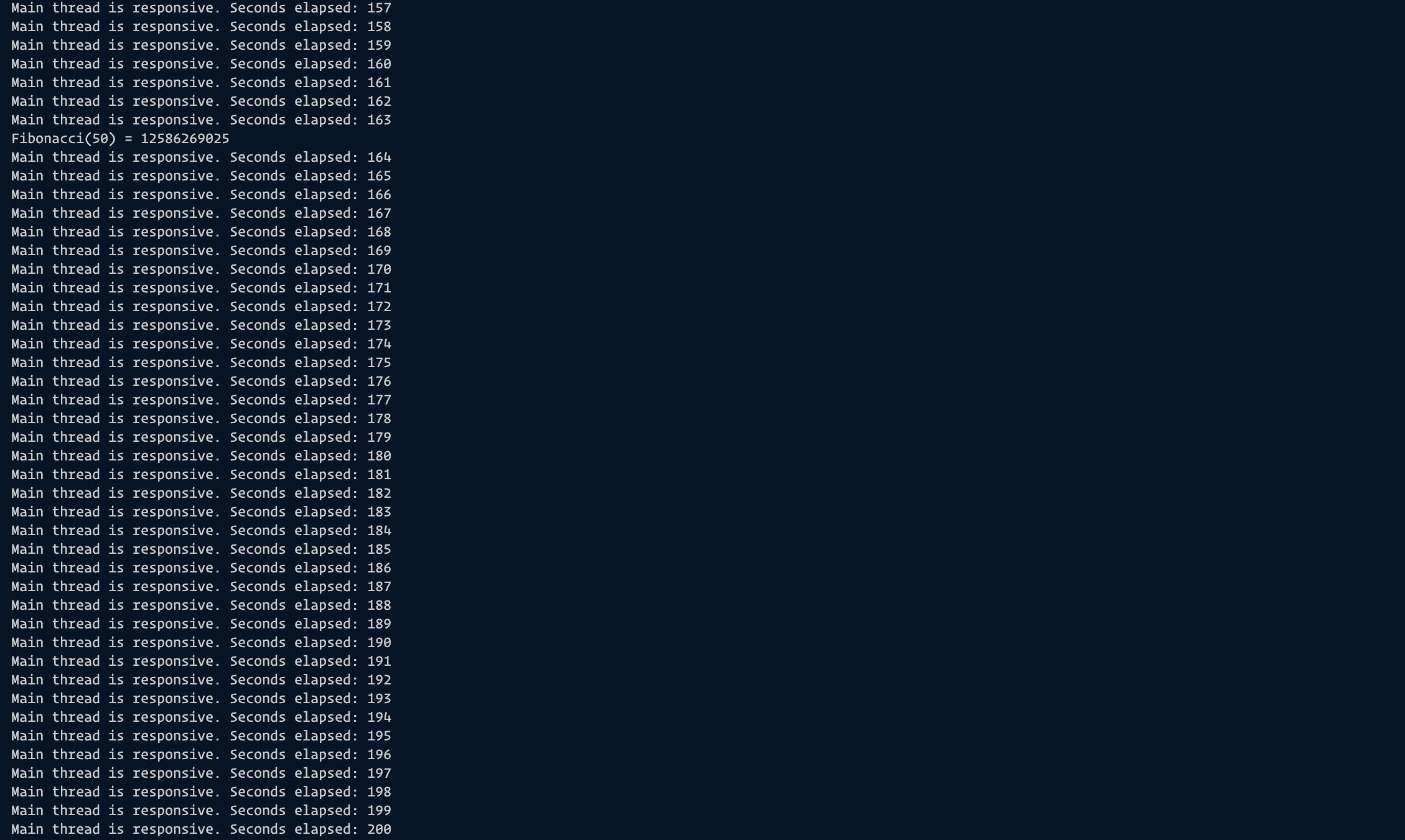
It took approximately 2 minutes an 43 seconds before the result of the Fibonacci function executed and returned when run with Node.js Worker Threads which is 2 seconds more than it took the function to run and execute when run without Node.js Worker Thread. The major difference is, that with the worker threads, we can execute other lines of code succeeding the function without interference. This will also help us utilise our resources better.
Conclusion
Node.js being Single-Threaded, limits the ability of the programming language to be used on CPU-Intensive tasks but with the help of Node.js Worker Thread, we can achieve concurrency which is one of the ways to handle computationally intensive tasks.

